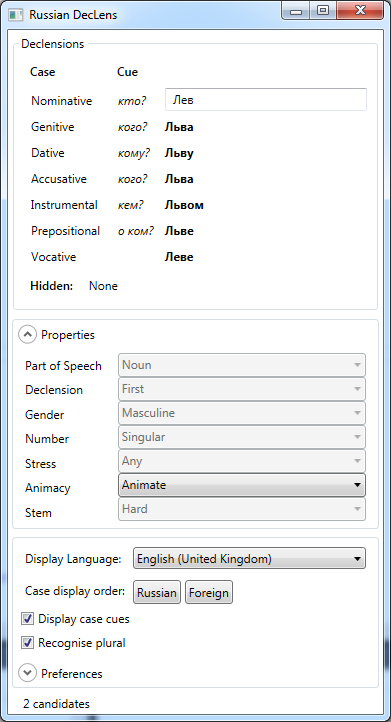
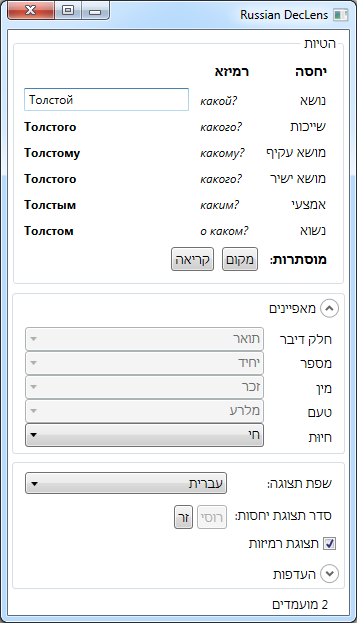
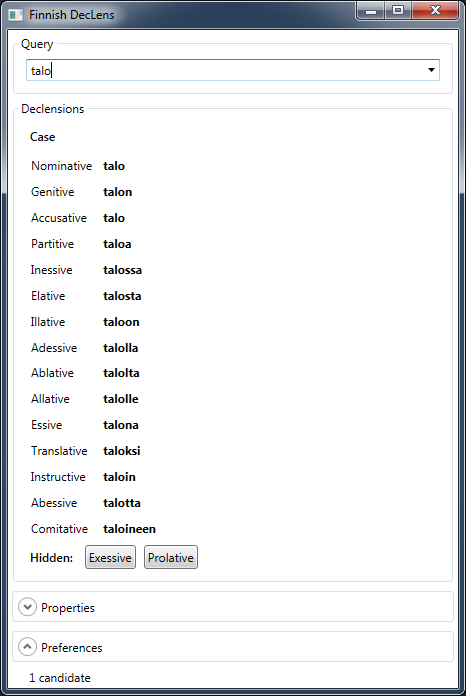
Shortcut reference links works well for English language because “English nouns are only inflected for number and possession” [w]. However, shortcut reference links do not work well for languages where nouns have more forms. For example, in Russian language nouns have 6 cases. Because of “variable nouns” in Russian text, an author has to use link labels very frequently:
... [Льва Толстого][Лев Толстой] ...
... [Льву Толстому][Лев Толстой] ...
...
[Лев Толстой]: https://en.wikipedia.org/wiki/Leo_Tolstoy
But frequent using link labels harms text readability.
Alternative approach would be using multiple link definitions, e. g.:
... [Льва Толстого] ...
... [Льву Толстому] ...
...
[Лев Толстой]: https://en.wikipedia.org/wiki/Leo_Tolstoy
[Льва Толстого]: https://en.wikipedia.org/wiki/Leo_Tolstoy
[Льву Толстому]: https://en.wikipedia.org/wiki/Leo_Tolstoy
...6 definitions total...
Main text is quite readable, but this approach is not so good because of duplication of link destinations (and link titles).
I would like to have some ability to avoid duplication.
One possible form could be:
[Лев Толстой]: -
[Льва Толстого]: -
...3 more cases...
[Льву Толстому]: https://en.wikipedia.org/wiki/Leo_Tolstoy
I. e. link definition with dash (or another dedicated character) instead of link destination and link title uses destination and title from the next link definition.
Alternative solution could be using regular expressions, e. g.:
[!Лев Толстой|Льва Толстого|...|Льву Толстому]:
https://en.wikipedia.org/wiki/Leo_Tolstoy
or
[!Л(ев|...|ьва|ьву) Толст(ой|...|ого|ому)]:
https://en.wikipedia.org/wiki/Leo_Tolstoy
Exclamation mark (or another dedicated character) denotes the label is a regular expression, not a literal.
Any comments on that?
BTW, Mediawiki (Wikipedia engine) uses another approach to the problem: If a link is followed by a word with no space, e. g.:
[[a]]b
They use a as link label, but concatenates a and b to form link text.
It allows to append endings to link labels. It helps a little but not too much. For example, it does not work for my example with Leo Tolstoy.