Numbered rows, suggestion
| header1 | header2
---|---------|---------
1. | cell |
1. | | stuff
This would act somewhat like a numbered list putting a 1, and then a 2 respectively before each row.
Numbered rows, suggestion
| header1 | header2
---|---------|---------
1. | cell |
1. | | stuff
This would act somewhat like a numbered list putting a 1, and then a 2 respectively before each row.
I am a bit late to this discussion, but here is my 2 cents.
I somewhat like the complex table and not the simple table. My main beef with the simple table is how to recognize it as a parser when parsing. Even |----| is better because it clearly indicates that it is a table. How does the Simple Table example definitively declare itself to be a table?
On the multiline, less issues, but still some. Like the option of a newline as a row separator, but would like to have another option available as well. Questions still remain on how to deal with column and row spans for tables, as well as alignment specifications.
Pandoc doesn’t seem to have any trouble. That example is after all what Pandoc supports. If I remember correctly it’s the line that separates the header from regular rows that is key. But to be sure take a look at the Pandoc docs.
The human eye sees a table because it sees the vertical columns of white space that delineate table columns, much like it sees horizontal lines of white space (i.e. blank lines). I’ve been working on a parser that does the same. Turns out it isn’t that hard, no AI needed: simply treat any vertically aligned white space that is 2 or more characters wide as a column delimiter.
The human eye perceives blank columns much like it perceives blank lines.
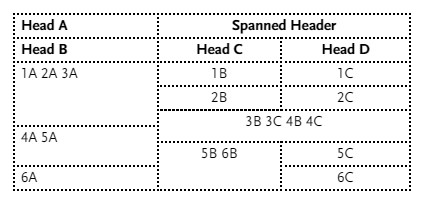
For what it’s worth, we’ve implemented an extended version of Github’s markdown tables to include multiple header rows, column spans, and row spans. Inspired by some of the ideas here but modified
based on user feedback. Our userbase of 100,000 + users seems to be pretty satisfied with this approach.
Column spans are signified by simply collapsing multiple right-hand pipes together.
Row spans are signified with a ^ immediately before the closing pipe(s).
| Head A | Spanned Header ||
| Head B | Head C | Head D |
|:-------|:------:|:------:|
| 1A | 1B | 1C |
| 2A ^| 2B | 2C |
| 3A ^| 3B 3C ||
| 4A | 4B 4C^||
| 5A ^| 5B | 5C |
| 6A | 6B ^| 6C |
The table syntax used in Spaceship (https://github.com/jeffreytse/jekyll-spaceship) is pretty good. An addition that needs to be through through is cell wrapping.
This looks great! An intuitive-enough format. I would love to see this in Pandoc. When you say “we’ve implemented”, what does this mean? In some proprietary project? I’ve been monitoring Markdown reader - support new table features · Issue #6317 · jgm/pandoc · GitHub for quite some time.
We implemented it in an open-source project as an extension to Marked.js. You can find it as an NPM package at marked-extended-tables - npm
Curious - how do you differentiate a column span from an empty cell?
| Head A | Spanned Header ||
| Head B | Head C | Head D |
|:-------|:------:|:------:|
| 1A | 1B | 1C |
| 2A ^| 2B | 2C |
| 3A ^| 3B | |
For example, would this empty 3C cell still collapse or would it leave the cell below 2C empty? Does the collapse only happen if the pipes are consecutive without spaces between them?
Column span only occurs if the pipes are adjacent. In your example you would just have a normal empty cell in 3C because of the whitespace between the pipes.
Sweet! Thanks. Sounds like a pretty solid solution.
This is basically a subset of what I suggested in my comment
https://talk.commonmark.org/t/tables-in-pure-markdown/81/134. I’m glad to
hear it has been working well for your users.
In addition to row/colspans, my suggested syntax included:
I think these are both important. But getting the details right about how the
rowspan syntax works with the cell continuation syntax might be a bit tricky.
Other things people have requested:
@aoudad’s comment has a lot of nice suggestions for these:
https://talk.commonmark.org/t/tables-in-pure-markdown/81/145.
In pandoc people have also requested these features:
It’s very tricky to figure out what is the right level of complexity to
suport.
Actually, I think the table syntax that is most compatible with the Markdown
philosophy of prioritizing source readibility is grid tables:
https://pandoc.org/MANUAL.html#extension-grid_tables. Pipe tables look
increasingly like line noise the more features are added, while grid tables
look just like tables. But grid tables seem quite unpopular due to the need to
align columns.
This is basically a subset of what I suggested
Yep that’s where I got most of the structure from. It seemed the “cleanest” out of everything I saw, and was easy to lay over the top of existing GFM standard tables without breaking what is already out there.
As for your other items:
My syntax allows column alignments following the GFM standard of colons and dashes.
My syntax simply concatenates adjacent row-spanned cells together with a space. This allows the user to use all of the vertical space in a row-spanned group but yes, it does not allow multiline blocks.
Would it be worth supporting pipe tables only for simple cases? If your table gets to a certain level of complexity and is becoming unreadable it is probably a good idea to switch from pipe to grid tables.
This would be line with other Markdown features, for example setext headings are only supported for h1 and h2, requiring the writer to switch to atx style for h3-6 headings.
Can you share the data and or anecdotes behind that observation?
Can you share the data and or anecdotes behind that observation?
I don’t have data, this is just my memory of conversations going back many years.
Basically there’s a split in the Markdown community between people who use Markdown for long-form writing (documentation, articles, books) and those who use it mainly for things like Reddit or Stack Overflow comments. For the latter, grid tables are a problem because they are working in text boxes which often use proportional-spaced fonts, so lining anything up is next to impossible.
I assume when you say block-level, you’re excluding just chunking an HTML <br> in the table to create a newline - this works on SO/SE, which makes for useful formatting in tables even without bullets.
I’ve used grid tables on SO/SE (posts, not comments)… the only way they work is if you put them in a code fence so that they’re fixed width. It does work, and we did it for years before we implemented markdown tables… but my thumbs definitely got tired from all of the spaces you needed to use to keep everything aligned.
I will say, there were some perks to it that you can’t really replicate in MD tables.
So, they’re not terrible and they do have some functionality that’s nice.
(Separately from the above)
One of the biggest asks we’ve seen from community members (and one of my biggest frustrations) has been the ability to control the column width which is separate than column span. I don’t know that I’ve seen much discussion of this and I’m not sure whether there’s a viable solution to allow people to call out a max column width, for example (either in percentages or px).
(Separately from the above)
One of the biggest asks we’ve seen from community members (and one of my biggest frustrations) has been the ability to control the column width which is separate than column span. I don’t know that I’ve seen much discussion of this and I’m not sure whether there’s a viable solution to allow people to call out a max column width, for example (either in percentages or px).
Pandoc does have a system for this.
For grid, simple, and multiline tables, widths are calculated based on the widths in the source.
For pipe tables, if one of the lines extends beyond 72 columns (configurable), then relative widths are calculated based on the widths of the separator lines.
Hi all!
I hope it helps, I saw this amazing discussion and this would be my simple idea to help. I think it could be something like this:
`` table A markdown editor might offer to import CSV, TSV, … files into markdown tables, but those data formats should not become a valid table syntax themselves, because their human readability is severely impaired.