This is a good point, the list markers might not match the rendered output. I’ve been assuming that authors would update their lists to the actual letter used, e.g.
a. First item
b. Second item
c. Third item
instead of the lazy style:
a. First item
a. Second item
a. Third item
It would only be in the first case that authors could accurately refer the starting letter. However, I also think that at least in smaller documents, the author would clean up their lists to use the literal letter marker, and manually change the letter to refer to the correct list item in other parts of the text. This is, after all, what you would do in a plain text file, which is what Markdown is in it’s raw form. The advantage of doing it this way, rather than requiring a special reference syntax, is that authors can create and refer to letter ordered list without any special knowledge besides how to write a plain text document; this makes the syntax ideal for casual forum posts, etc.
Perhaps some kind of reference syntax (similar to how links and footnotes work) should be added for more complex scenarios.
I would argue that a good reason for inclusion of letter-ordered or a roman numeral-ordered lists in commonmark is that people commonly write these in regular text files
As a markdown user, when I’m writing, I’m writing a text file which also happens to magically compile to give a rendered output.
Having numeral lists be rendered but not letter / roman-numeral lists causes an inconsistency in rendering, which forces me to mentally change my writing style to just use numeral lists. I don’t want this mental overhead of remembering that I must use only certain kinds of lists because only certain kinds work with markdown.
Since both numeral and letter lists work in the text, I expect them both to behave consistently after rendering as well.
Common use-cases:
1. Item
a. Sub-item
b. Sub-item
**Definition**: Mathematical definition, and conditions (i) - (v) hold:
(i) First condition
(ii) Second condition
(iii) Third condition
(iv) Fourth condition
(v) Fifth condition
I'm taking notes on something, the reference text using a) b) c)
1. But
2. My List
3. Uses 1, 2, 3,
So now whenever they refer to c, I have to remember to translate it to 3. Which sucks.
Bump. (Is bumping allowed?) Or, I second this. Whichever.
I found another use case, which is that a lot of software licenses contain letter-ordered or roman numeral-ordered lists. They don’t convert naturally to Markdown without altering the license text (bad) or cluttering it up with HTML code.
I checked several popular licenses and many have lettered lists: the GPL 3.0 (section 5), Creative Commons 4.0 (section 1), Apache 2.0 (section 4), etc.
Since GitHub is the top location for open-source software, and it almost encourages that every document be posted in Markdown (e.g. README.md is automatically displayed on the repository home), this seems like a really big omission.
I’m in agreement. I argued for lettered lists in our original discussions about the spec, but for some reason there was resistance. We’ve had them in pandoc for a decade at least, and they are pretty unproblematic. (We even have roman-numbered lists.)
One tricky thing is that names with initials can sometimes look like a letter-ordered list: e.g.
B. Russell says...
In pandoc we avoid problems of this kind by requiring two spaces after letter-ordered lists starting with a capital letter.
Initial letters with an abbreviation dot are similar to numbers with an ordinal dot (some languages use 1., 2., 3., 4. where English has 1st, 2nd, 3rd, 4th, e. g. in dates). The solution to distinguish them from list markers at the start of a line should be similar as well, especially for lists that interrupt a paragraph without a preceding blank line and for single-item lists, which together constitute an issue that blocks v1.0.
Since i. and i) would be even more ambiguous if Roman numerals were to be supported as ordinal list values, one could amend and restrict the valid syntax choices, e. g.:
I frequently try to create nested lists on Discourse and am frustrated by the inability to do so using letters and roman numerals, even in a conservative lowercase-only subset.
My minimum viable feature set would be simply a conservative parsing of
a) / a.
b) / b.
c) / c.
…
and
i) / i.
ii) / ii.
iii) / iii.
…
This might be made easier by requiring indentation, as with the current list formats.
A more feature complete implementation would resemble @crissov’s list above,
It’s not entirely trivial to implement, because in addition to @Chuck_Roberts’ suggestion that
there would, of course, also need to be several parsing rules added to translate the different types of lettered and roman numeral lists in markdown to the equivalent in HTML/CSS.
That said, I, for one, welcome the trivial implementation of this into CommonMark, and eventually maybe the extended implementation.
I know that this is an old request that had no good answer, but I recently implemented a hack that might work as a syntax for this. Trying to parse the many different formats of list labels in human text is clearly insane, so the logical conclusion is to add some syntax for that which looks readable enough and requires minimal additions. I ended up using
* [a] blah blah blah
with a simple regexp post-processing implementation that looks for <li>[something] and changes that. It could conflict with an anchor reference, but (a) that would be rare given that anchor names are usually longer than list labels, (b) with my hack, an existing anchor would not be modified. (A proper implementation can barf instead.)
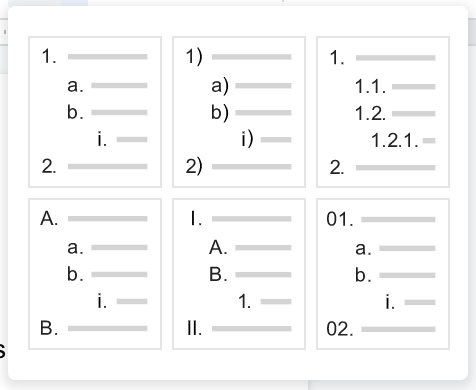
Enumerated lists (a.k.a. “ordered” lists) are similar to bullet lists, but use enumerators instead of bullets. An enumerator consists of an enumeration sequence member and formatting, followed by whitespace. The following enumeration sequences are recognized:
arabic numerals: 1, 2, 3, … (no upper limit).
uppercase alphabet characters: A, B, C, …, Z.
lower-case alphabet characters: a, b, c, …, z.
uppercase Roman numerals: I, II, III, IV, …, MMMMCMXCIX (4999).
lowercase Roman numerals: i, ii, iii, iv, …, mmmmcmxcix (4999).
In addition, the auto-enumerator, “#”, may be used to automatically enumerate a list. Auto-enumerated lists may begin with explicit enumeration, which sets the sequence. Fully auto-enumerated lists use arabic numerals and begin with 1. (Auto-enumerated lists are new in Docutils 0.3.8.)
The following formatting types are recognized:
suffixed with a period: “1.”, “A.”, “a.”, “I.”, “i.”.
surrounded by parentheses: “(1)”, “(A)”, “(a)”, “(I)”, “(i)”.
suffixed with a right-parenthesis: “1)”, “A)”, “a)”, “I)”, “i)”.
I find the list formatting where you have the ability to easily reference subheadings really useful in long lists. So you’d have top levels that are numbered followed by subheadings that use letters, roman numerals, etc. This is a pretty standard format in many programs for creating documents, such as Google Docs -
In MD, my only option is to mix numbers with bullets. It’d be nice to have a way to allow other options.
On our platform we’re working on mixing rich text input with MD - we render everything into MD but people can copy and paste rich text into an editor in rich text mode and we’ll convert what we can. It’d be cool if the spec allowed for more options because it’d allow us to retain more of the formatting we receive from a rich text document.
(@vas: I think that anyone involved with the design knows rst well, @jgm definitely knows it – see pandoc.)
@Crissov: That’s exactly what I’m suggesting, but I missed the fact that it’s similar to the GH syntax for checklists… On the positive side, it shows that using this syntax won’t lead to problems, but the minor negative is that it would be a problem for existing uses of - [x] as a checked item rather than an x label.