Wild idea. How about unifying code for plugins and code formatting. The average user cannot tell the difference anyway, so why bother.
~~~ youtube { vid=09jf3ow9jfw }
Here is a video of my cat.
~~~Wild idea. How about unifying code for plugins and code formatting. The average user cannot tell the difference anyway, so why bother.
~~~ youtube { vid=09jf3ow9jfw }
Here is a video of my cat.
~~~The markup looks leaner and intuitive, I wonder how it would behave with other formatting needs (e.g. sphinx/docutils bridging).
+++ nielsle [Jun 02 15 13:23 ]:
[1]nielsle
June 2Wild idea. How about unifying code for plugins and code formatting. The
average user cannot tell the difference anyway, so why bother.Here is a video of my cat.
One advantage of this sort of approach is that requires no
changes in the parser. You just need to go through the AST,
looking for specially marked code blocks and transforming
them to links or whatnot.
Compare my comment here.
One nice thing about most lightweight markup languages is that they do not rely on English words for tag and attribute names or keyword values since they are repurposing ASCII punctuation/non-alphanumeric characters instead. All those extensions with key-value pairs and explicit names harm that principle. They are a step back. They are not based upon prior art, i.e. actual practice in plain-text media. They are not in the spirit of Markdown. They impose coder habits onto a general purpose language. They must be considered harmful. They are a bad idea.
That being said, there is a place for names that are not predefined, i.e. IDs and classes, or that are proper names, e.g. language names for automatic highlighting in code blocks. IDs can be auto-generated, however, in most if not all cases.
In other words, if you want verbose tags you have come to the wrong place and should use XML/HTML or (La)TeX instead.
+++ Crissov [Jun 15 15 23:47 ]:
One nice thing about most lightweight markup languages is that they do
not rely on English words for tag and attribute names or keyword values
since they are repurposing ASCII punctuation/non-alphanumeric
characters instead. All those extensions with key-value pairs and
explicit names harm that principle. They are a step back. They are not
based upon prior art, i.e. actual practice in plain-text media. They
are not in the spirit of Markdown. They impose coder habits onto a
general purpose language. They must be considered harmful. They are a
bad idea.
This is a real advantage of Markdown (and its ilk) over LaTeX, DocBook, HTML, etc. If you write in Swedish, your source document looks like Swedish – not Swedish with a bunch of English words mixed in. So I’m against hard-coding English words into the syntax.
Of course, going too far in the other direction makes your source document look like Perl.
Just discovered and played around with @vitaly’s markdown-it container plugin which allows the most basic form of 3. Container Block Directives proposed above. Pretty cool! Looking forward to hear your experiences when you’ve got more user feedback etc.
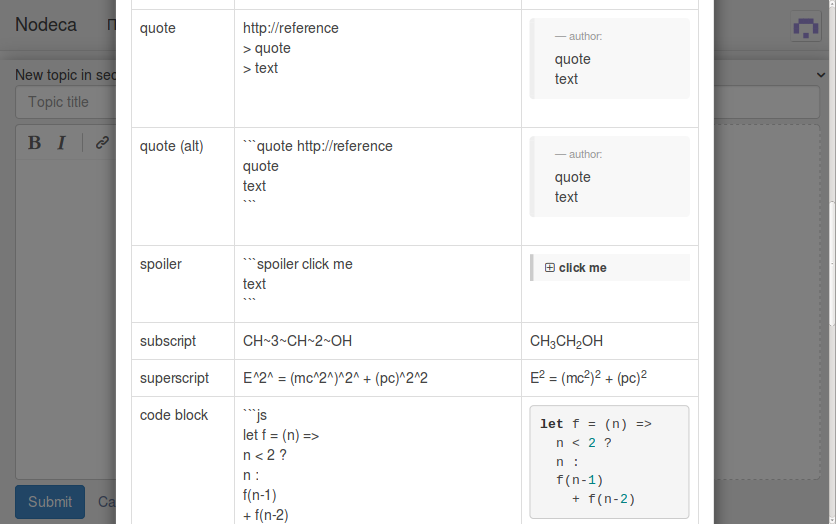
We use it for quotes & spoilers:
Don’t be confused wit ``` syntax. That’s for convenience. It overrides defaults when keywords quote and spoiler used, and run our plugin to allow markup in internal content.
I meant:
::: warning
here be dragons
:::Yup mb21, I would be interested to see how the custom container function in the wild. Seems to be fine so far.
What would you think of the detail block as a solution for spoiler blocks w3schools page on the <details> tag
^^^ classname summary text
full content here
^^^
<details>
<summary>summary text</summary>
<p> full content here </p>
</details>
e.g.
^^^ spoiler for harry potter ^^^
snape dies
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Unfortunately, the details element is not widely supported by browsers.
 then at least as a ‘detail’ block within commonmark, but expressed in html in whatever best way we can do for now (e.g. how we do spoiler text in html nowadays).
then at least as a ‘detail’ block within commonmark, but expressed in html in whatever best way we can do for now (e.g. how we do spoiler text in html nowadays).
There is no need for using a <detail> element which is already kind-of-defined in HTML, but may or may not be recognized by browsers and other HTML consumers: if the purpose (from the point of view of the CommonMark processor) is to “wrap” an uninterpreted block of raw text (which is what I take from @mofosyne’s remark about “to see how the custom container function in the wild”), one better “invents” an element type name which does not conflict with popular DTDs like HTML.
This works already quite nicely for an element type called <mark-up> in my little project (not exactly “in the wild”, but we’ll go there): As the CommonMark processor cmark_filter does now, so will other mark-up processors recognize and process this special “container element” type only, until it is vanished from the output document.
Something along those lines is used also by recommonmark (e.g. to bridge rst-specific constructs that are too annoying to support natively)
That’s an interesting key word you mentioned there: “recommonmark”—so thank you for the hint!
Yes, that seems similar to the concept I’ve based my project on; but so far I only took a glimpse of the first page that popped out of the Google search …
[The rst means reStructuredText, if I understand correctly.]
Exactly and probably this part should be agreed soon, since would be nice to be able to use it.
On the other side, I wouldn’t see any harm in allowing either colons : or equality signs = when specifying attributes, or allowing optional commas ,. The values on the right-hand side of a key-value pair shouldn’t contain either symbol and the additional overhead for parsers is minimal.
Markdown has some relations with HTML (e. g. it allows HTML code), so HTML attribute syntax is preferable.
I would like to specify attributes for RDFa. In such a case values can have colons:
[tiger]{property=ov:preferredAnimal}
It seems like this discussion has significantly stalled; is that right? I’m trying to research what the current state of extending Markdown is, and this thread seemed like the place. Is that true?
As I understand it, the priority right now is to get version 1.0 of the core CommonMark spec finalized before adding extensions. See this thread about adding tables to CommonMark:
That’s a very subjective one ![]() I prefer the equal ‘
I prefer the equal ‘=’ sign.
Good point!
If we’d use colons, I would leave out the empty space after the colon. It looks good on multline listings but not on a single line. It competes with the literal spaces, that belong to a sentence and, thus, creates line noise. I think, here, perception of the line is different as it is in source code, where I prefer spaces after most of the symbols.
But I can live with either. Though, for uniformity, we should settle on only one.
I think the space " " itself creates ambiguity. Take programs, that let you add tags (to posts, etc.). This way I can not have spaces in them. Then I forget about it, assume a comma to be the seperator and bam! I have an unneeded tag.
Comma ‘,’ is what is used to list stuff, within a sentence, in literature. This is why we should be consequent about it. We also use them in arrays and in function signatures in programming. Empty space means separation of words, not items.
Is there further progress on this, or is it stalled?
On the other hand, spaces do have precedent for item separation. Shell is one, and Fish shell notably goes all in on this. The other notable (and relevant) example off the top of my head is HTML’s tag attributes.
As such, for consistency with HTML, I’m against commas.