After developing the attributes blocs for Stylo I came out with an implementation which follows in part the draft proposal from @mb21 and the specifications stated in my previous message (which this message replace).
All examples below, which are loosely inspired from the @mb21 draft proposal, will apply the following CSS and I show the final rendering in Stylo:
.blue {
color: blue;
}
.red {
color: red;
}
.green {
color: green;
}
.pink {
color: pink;
}
This proposal follows the draft proposal on many points but simplifies it on others and add three new capabilities:
-
Possibility to add attributes blocs before bloc.
-
Attributes aggregation of all attributes blocs pertaining to a bloc.
-
Inline attributes blocs are applied to the inline element defined before them, if there is no such element, they apply to the bloc in which they are defined: the enclosing bloc.
There is also some difference with my last proposal: instead of allowing attributes blocs after only for terminating blocs, I followed the simpler rule of allowing an attributes bloc one the line below any bloc, like the draft proposal is suggesting.
On the simplifications side,
-
no requirement for the attributes blocs to follow the bloc indentation to apply to them, unless normal parsing implies such necessity e.g. a list of paragraphs
-
also removed, is the necessity to have spacing (or no spacing) between the attributes blocs and the elements. The three rules below cover all cases without the need of such rules.
-
no line feed are allowed inside attributes blocs. This last rule could have become a problem as more attributes are added to an element, but since aggregation is supported they can just be added separately, like here:

Rules
So, here are the modified/new rules:
-
if an attributes bloc is one line below a non-attributes bloc, it is always assigned to this bloc (the one before). One line below in this definition, means there is no blank lines between the end of the non-attributes bloc before and the attributes bloc, otherwise we get unintuitive results with list continuation where a list is terminated by the attr-bloc a couple of lines below but is still considered on the line below because of lazy list continuation.
-
if an attributes block is placed before (see definition of before and after below*), it is assigned to the first non-attributes bloc element after
-
otherwise, it is assigned to the first element on the left on the same line, unless this element is an attributes bloc, in which case it should apply to the first bloc it is contained in.
*An attributes bloc can be defined inline e.g. inside a paragraph, or as a bloc, at the root or inside another bloc. _ Before _ or _ after _ refers to the relative position of an attributes bloc relatively to another bloc level element under the same bloc or the root. The notion is quite intuitive in fact:
Attributes bloc after:
Example 1:

Or:
Example 2:

Attributes bloc before:
Example 3:

Or:
Example 4:
To be considered a bloc, the attributes bloc must not be followed by anything else than whitespaces:
Example 5:

Some examples:
ATX Headers:
Before:
Example 6:

inline:
Example 7:
![]()
or after:
Example 8:

are allowed.
Or inline:
Example 9:
![]()
One of the goal of this way of specifying attributes is to keep the same parsing as we would have without attributes bloc handling. In this case putting the attributes bloc after the closing header sequence would result in the attributes to be applied to the whole content including the closing header sequence as it becomes part of the content because it is not closing the header content. So this would probably be unexpected:
Example 10:
![]()
horizontal rule
Example 11:
![]()
Following these rules, we don’t care if there is spaces between the attributes bloc and the horizontal rule:
Example 12:
![]()
In my implementation, a line feed inside an attributes bloc invalidate it, the same as blank lines inside it:
Example 13:

Setext headers
Example 14:

fenced code block
As in the draft proposal, an attributes bloc can be put in place of the usual params or “info string” and become “syntactic sugar for classes”.
But attributes can be put before or after as with any other bloc element:
Before:
Example 15:

After:
Example 16:

Replacing the params:
Example 17:

Reference Links
In the reference links case, there is no need for spaces before the attributes bloc:
Example 18:

In the previous example, only the first attributes are propagated since it is the active reference (because it is the first one).
For now, in Stylo, the attributes propagation to the referencing links and images is applied. I am still not sure about this feature though. For me it agravates the problem on non-locality of the information and adds the necessity to look at the reference to know the attributes applied to the link or images. It is acceptable but not an ideal situation.
Paragraphs
As usual, attributes are supported before, inline and after:
Before:
Example 19:

Inline:
Example 20:
![]()
After:
Example 21:

Inline blocs, apply to the previous inline element unless, this previous inline element is itself an attributes bloc:
Example 22:
![]()
Example 23:
![]()
If the previous element is an attribute bloc then the attributes apply to the enclosing bloc:
Example 24:
![]()
There is no need for the attribute blocks to be indented exactly as much as the first line of the paragraph: if it is on the line below it applies to it:
Example 25:

Block quotes
No need for the attributes bloc to be indented as the block quote to apply to it, since it is on the line below at the same level, it is sufficient:
Example 26:

Example 27:

The same rules apply inside a bloc quote, :
Example 28:

Bloc indentation does not change anything:
Example 29:

But as we can see, depending on where the attributes belong they apply to different blocs (remember that red has higher priority than blue in the CSS style):
Example 30:

Example 31:

Example 32:

Example 33:

Lists
Example 34:

Attributes blocs that are not directly under a bloc are applied to the following one:
Example 35:

The same goes for lists inside another bloc, here a blockquote:
Example 36:

To get red color applied to the list, we need to put attributes bloc directly under it:
Example 37:

We can apply different attributes to the lists
Example 38:

Example 39:

Example 40:

Example 41:

Example 42:
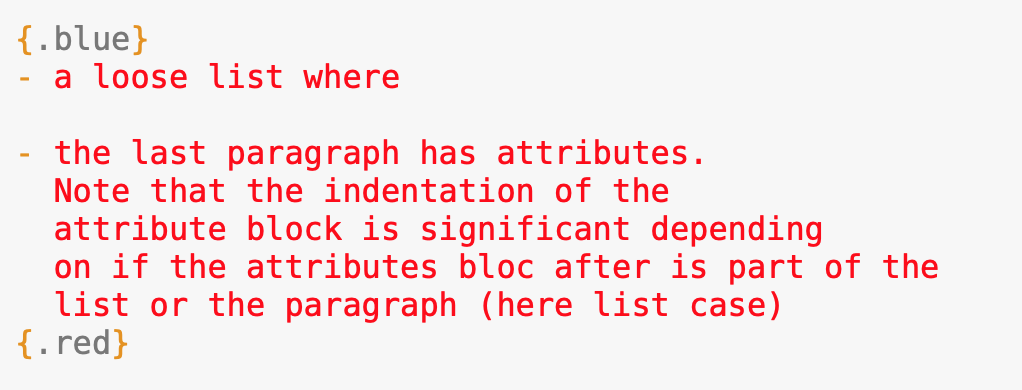
Example 43:

Example 44:

Pink class attribute is put on top:
Example 45:

The attributes can be put before for the list too:
Example 46:

inline code
The spaces don’t matter:
Example 47:
![]()
or
Example 48:
![]()
Example 49:

emphasis
Example 50:
![]()
Example 51:
![]()
links
Example 52:

Example 53:
![]()
Example 54:

images
Example 55:

Example 56:
![]()
Example 57:

reference
Example 58:

Example 59:
![]()
Example 60:
